

Original: Li Sheng
Elastic Search
In recent years, this is a very popular system for distributed search and data analysis
Trip
ES not only implements a large-scale logging platform in-house
At same time, ES is also widely used to implement search, recommendation and other functions in various business scenarios
My work
This is written in business search scene
Tell you what you think about data synchronization. Share some thoughts
Data synchronization is a very troublesome thing
Very difficult. It's not that hard
Your hotel's demand roughly includes full amount
Yes
Sequential serving from Hive, MySql, Soa
Get data from various data sources like Mq
Part of data needs to be calculated or converted and then synchronized with ES in near real time
So that users can find it
My writing style makes it easy for you to understand
Therefore
2. Each article is associated with a tag. Save it in article_tag
table3. The tag name in tag table must also be included in ES index. To use tag name to search for articles
Previously, to synchronize such data, you had to enter ES and pseudo-code for assembling data of one article
For example, as follows
List tagIds = articleTagDao.query("select tagId from article_tags where articleId=?", articleId);List tags =tagDao.query("select id, name from tags where ID in ( ?)");ArticleInEs articleInEs = new ArticleInEs(); articleInEs.setTagIds(tagIds); articleInEs.setTagNames(tags.stream().filter(tag-> tagIds.contains(tag.getId())).map(TagPojo ::getName).collect(Collectors.toList()));< /pre>The assembler code of just tag information is very cumbersome, but real situation is much more complicated
For example
There might be a dozen or even a dozen ES index fields, or consider code
SQL
Performance and business logic
The data assembly task itself is no longer relevant, not to mention that there may be business logic to deal with
Because Ctrip uses ES in many business areas
There is a strong need for an easy-to-use platform or tool to do this job
So everyone can get rid of tedious and repetitive code and focus on finishing business itself
For example, there are many similar implementations in open source community
similar
elasticsearch-jdbc, go-mysql-elasticsearch, Logstash, etc...
In my estimation, there are following problems. Can't land
1. Shared tools are config based which is very handy
But for security reasons
We can't get a textual database connection string in production and we can't set up a data source
2. Sometimes data received from DB needs to be processed before being sent to ES
A simple configuration-based approach is not enough
3. Username ES
Password, etc. We don't want to appear in configuration
You need a single place to manage your connection informationin order to ensure safety and ease of maintenance
4. Data Collection
Some scripts are more complex, and setting up these tools can be more difficult to write than code
5. Additional data sources
Sometimes MQ cannot be updated using configuration
6. Some tools are separate command lines
Cannot be combined with our JOB (JAVA based)
I have found these tools to be more suitable for simple DB data or scenarios that already have flat DB tables
One of our scenes is more difficult
If there is a flat table, then synchronization with ES will not be difficult
We need to build a wheel to solve all problems
In addition to accommodating scenarios that aforementioned open source tools do not support, they also retain their configuration based mechanism
Achieve only what is necessary
SQL, ES mapping, and adding necessary data sources can complete job of creating an index
The structure of general synchronization module is as follows
I use different sizes to represent component design ideas
3.1 By index method
1. The first one is a full sync, because full amount is entire index change
Therefore, it is necessary to ensure stability, and also to make sure that problematic indexes are not created
Full amount will create a new index from scratch
Before synchronization
This will change index mapping number_of_replicas to 0, refresh_interval to -1 and other options
For faster indexing
At same time, _indexTime field is added
Indicates when this data is updated, which is used for subsequent error checking, comparison, etc.
After indexing is complete
Added operations such as force merge, restore mapping change, _update
Make sure created index is as compact as possible
Make sure index health indicator is green over time to avoid prolonged instability after switch is not fully ready
Finally, check if difference between final number of valid documents in this index and number of documents in actual online index is within allowed configuration range
If it doesn't exist, this index is considered invalid, delete contents of this index
2. The second is MQ increment
Ctrip internally uses QMQ to receive MySql changes from Otter and database tables will be changed in MQ
Field information
Therefore, MQ parsing rules can be implemented purposefully
This way it's easy to get all documents in ES via MQ
Section Index
Because in most cases there is less information in MQ, so in most cases
It is recommended to use third method to increase after getting MQ
3. The third one is identifier increment
The user passes in a list of IDs to be indexed and uses ID to create a complete document according to configuration and send it to ES
Model to simplify whole indexing process
This is most commonly used method and is also very handy for temporarily updating data
If provided identifier is not found in final data
The corresponding data in ES will be removed to deal with situation where data is physically removed from database.
4. The last one is time increment, component will maintain update time of each index
To make sure incremental JOB scrolls when executed
New data can always be entered into ES as soon as possible
Because program will require regular checking of latest data in specified table
Therefore, it is not very DB-friendly, and in most cases we do not recommend using this method for serving data.dexes
The scripts above
Total Amount, ID, and Time Increment need to be configured to create a full document
Make sure full document is sent to ES each time
From an implementation point of view, it is necessary to ensure that increment that occurs in process of establishing full amount
Before switching newly created index to web use
Create an incremental sync, this step is usually handled in MQ
3.2 According to data source
1. SQL based configuration
Complete tag association of related articles, this build scene is very simple
Sometimes it is also necessary to simplify SQL or optimize SQL performance
Request submitted separately
Due to common logic, there are built-in code plugins to read and assemble this data type
2. Code-based processing
Suitable for similar SQL, which is inconvenient to execute and requires data to be requested from SOA services
Or a scene where data needs to be processed in a complex way
This requires you to use your own custom plug-in as required by component to provide data to component for unified processing
3.3 Modulo
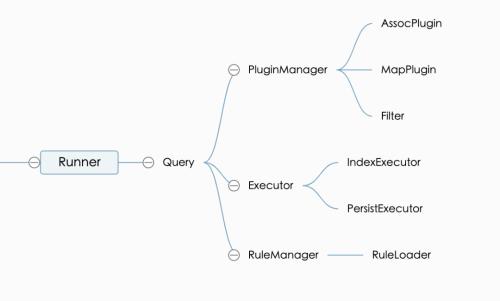
1. Runner
This is common entry point of component call, it is responsible for parsing parameters and generating Executor
Initialize modules like Rule etc.
Due to convenience of encapsulation, Runner can interact with a distributed JOB to complete parallel creation of same index
To speed up creation of entire index, this parallel method is widely used internally
2. Request
It is control center for entire internal process
Responsible for building SQL and reading database according to parameters passed to Runner
Scheduling an executor and plugin
Different indexing methods require different SQL preprocessing
Similar time increments should support incremental time, etc., and they also run in this module
To make development easier
The Groovy script specified in run configuration is also implemented in Query
Data can be processed in script before it gets to Executor
In some simple scenarios, it is very easy to implement data filtering and processing
3. Plugin Manager
Responsible for parsing plugin configuration, instantiating plugins, managing plugin calls, etc.
I've summarized common data assembly methods and provided some built-in plug-ins
In principle, most database-based data collection and assembly can be done
For example, Assoc plugin
Aggregation scripts such as article tags can be executed
The Map plugin can execute mapping scripts similar to Map
Filter supports simple filtering of each piece of data
Similar to HTML, deduplication, etc.
To reduce load on database
All built-in plugins support setting data cache time, and within allowed time, priority is given to data stored in memory
4. Artist
Used to get data from Query to perform actual landing action
There are two built-in executors that users can choose from depending on situation
Index Executor
Submit data to ES via bulk mail to update ES index
At same time, actions such as creating a new index, updating status of an index, switching aliases, etc.
PersistExecutor
Will write data from Query to a flat table in specified database
You can also see that if you have a flat table, it's very easy to sync with ES
5.RuleManager/RuleLoader
Used to complete loading and managing rules
Support for reading configuration from unified QConfig of company or resource folder of current project
The plug-in performs same detection as ES and provides appropriate error reporting for configurations that are out of specification to reduce data errors caused by configuration issues
In real work
There are also scenes from Hive in ES
Because it is outside scope of this component, it is not discussed in this article
We also currently have a script where ES-Hadoop is used to complete full index build
Use this component to support incremental loading
At present, dozens of indexes from several enterprises use this component to maintain indexes
R&D staff are most focused on business logic
Don't worry about cumbersome repetitive code
Via this component
Data from different data sources can be imported using an assembly. Exported to an ES index, it can also be exported to a flat DB table
Therefore, it can also be used in some data synchronization scenarios





Related
Ctrip. All data in Elasticsearch system. What features? let me tell you...
What is use of new "Insight" feature displayed in hotel's OTA system? let me tell you
How does Xiaohongshu marketing work? What system model? What is the marketing strategy? let me tell you
How does Ctrip system work? I am a technical data operator of Ctrip. Let me talk about this with AWS.
What is .ARIMA timing system. on Ctrip.com? Let me tell you, this is for business volume forecasting.
Hotel: Relationship between process management and system What's going on? let me tell you
Why messages are delayed in Ctrip BookKeeper How system works I'll tell you
What is cognitive evolution? Let me tell you basic logic of live streaming.
In 2023, hotel will face 6 biggest challenges. let me tell you
Success factors for budget hotels What conditions must be met? let me tell you...