

Original: Li Sheng
1. Background
Trip
Development of foreign hotel business
All over world
Overseas Suppliers and Ctrip IDC Headquarters
The amount of data transferred between them is growing rapidly
Technically
This growing amount of data is critical for cross-border networks
Dedicated line bandwidth
Latency, etc. make higher demands
Business
Due to current limited cross-border network line
Resources to improve business process efficiency and user experience
It also had some impact
About cost
A leased line of a cross-border network as an expensive resource
Simple
Leased Line Extension Will Hugely Impact IT Costs
So I started wondering if it's possible to go public
Combination of cloud services
Business characteristics of direct connection of hotel to solution
Bandwidth increase and ISP latency issues
Hotel
The direct connection system mainly uses automation interface
Implement system communication between providers or groups and Ctrip
Injecting static information
Dynamic Information
Order function, etc.
Everything flows and interacts systematically
Currently Ctrip
A large number of foreign hotel enterprises are connected through hotel direct connection system
here
What am I talking about
Mostly from Ctrip hotels
In process of migrating and deploying Direct Connect Services on AWS
Application architecture
Adjustment and cloud transformation
Technical and business benefits of using AWS
EKS during deployment
Amazon Elastic Kubernetes Service
DNS query
Latency and traffic between availability zones
Reduce costs
Some aspects, such as optimization, will be described in detail
2. Pain point
Ctrip Hotel
Direct foreign connections connected thousands of foreign suppliers
All interfaces
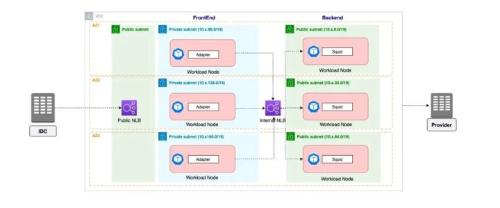
Access goes through a proxy
Figure 1 looks like this
Due to hotel's direct connection business characteristics
When a user asks to come, it will depend on number of people
Nationality
Members, non-members, etc. split into multiple queries
When most often
It is possible that one request will be split into dozens of requests
And request message is very large
Usually tens of kilobytes to hundreds of kilobytes
Although we
You may only want to return a small portion of information in message
But due to limitations of current architecture
All Only
All packets are requested and then processed
This is undoubtedly a huge waste of bandwidth
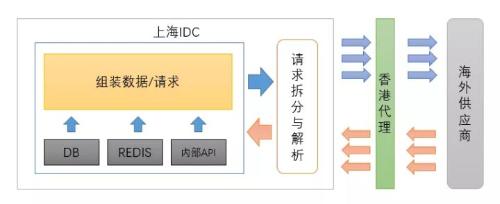
Picture 1
Simultaneously
Because there are suppliers all over world
All Requests
Responses must be exported via group proxy
resulting in a partial provider interface
Response depends on physical distance and latency gets longer
This will degrade user experience
3. Choosing a cloud service and a preliminary plan
One of main goals of this year
This needs improvement
Connect to network transmission capabilities of global providers
And postpone improvements. Improve user experience
Required
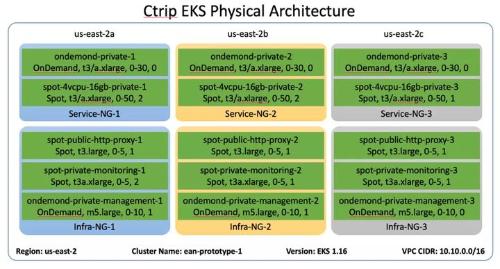
Cloud service provider with extensive distribution of resources around world
Coordinate Ctrip to access data as close to providers as possible
passed with several
Multiple rounds of exchanges between public cloud providers
Comprehensively consider technical level of each manufacturer
Service Capabilities
Price and many other factors
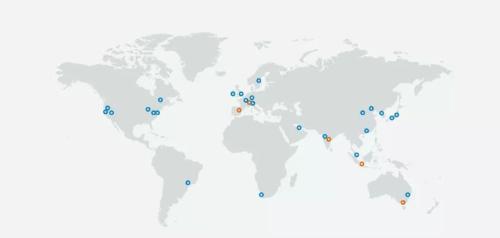
I think AWS is irrelevant in world
Coverage and networking
See rice. 2
AWS is distributed worldwide
25 regions and 80 availability zones
Provide a wide range of service options
At same time, data center is interconnected through its backbone
Improve data of various data centers in future
Opportunity between visits
Cloud Services
development and maturity
Service capabilities of field team
Response time
Pro level has obvious advantages
In end, I think
Choose AWS as your Cloud Service Provider Partner to Deploy Resources
Picture 2
For
Improved integration using resources in cloud
I recommend using IDC containerization
Deployment plan
As a last resort, consider making hosted container platforms highly available
Design and SLA
And compatibility with community
Using AWS
Hosted EKS Container Platform as Deployment Platform
Resource
I recommend
After service update
Wide use of Spot Instances as EKS worker nodes
Significantly reduce costs and increase efficiency
Using both options
Public Cloud Network and Platform Benefits
Relevant business was originally deployed at Ctrip headquarters IDC
Service deployment
Go to an overseas public cloud site closer to provider
Implement Ctrip and foreign
High reliability among suppliers
Low latency direct network connection
And some data
Pre-processing logic removed for pre-deployment
Move to an overseas public cloud
Only process valuable data
Instead of original, full amount of raw data
Compress and upload to Ctrip data center
To reduce load on cross-border network line
Improve efficiency of business data processing
Goals such as cost reduction and user experience optimization
4. Direct connection of hotel to cloud
I said:
4.1 Cloud Transformation of Cloud Business Applications
To fully
Convenience and cost optimization through use of cloud services
After research and analysis
I recommend
If application is directly migrated to public cloud
Although business will generate corresponding value
But cost will be relatively high
That's why we provide a direct connection service to hotel
Compliant
Optimization of cloud architecture. Related major adjustments
In following way:
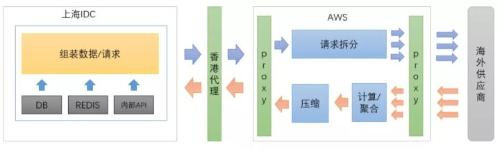
1. Access provider module in cloud
Reduce bandwidth to save bandwidth
Through a request from a proxy
Simultaneously reduce batch size of each request
Our approach should be to query
Partitioning logic moved to AWS
One user request at a time
There is only one request to exit through proxy. Answer
Simultaneously
We're on AWS
Remove useless attributes from message returned by provider
Then
According to business attributes to combine related
The node is finally compressed and returned
This achieves goal of reducing message size
See fig. 3
From current operational data
Entire agent
Bandwidth is only used up to 30-40%
Picture 3
Public cloud providers
A traffic-based pricing strategy is typically applied
Designing inbound and outbound networks
In process of accessing technical program
AWS NAT gateway will be used by default
This network
Traffic costs are relatively high
Given that a direct connection request to a hotel has a function
Typically, request message is less than 1 KB
Reply message
On average, from 10 to 100 thousand
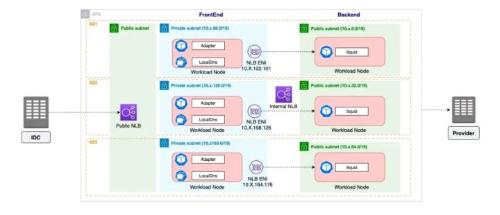
Use this feature
We switched to AWS
Squid standalone proxy solution based on EKS
See rice. 4
This way only outgoing requests
Messages are subject to traffic charges
There is no charge for a large number of incoming response packets
Thus, network traffic charges generated on AWS are significantly reduced

Picture 4
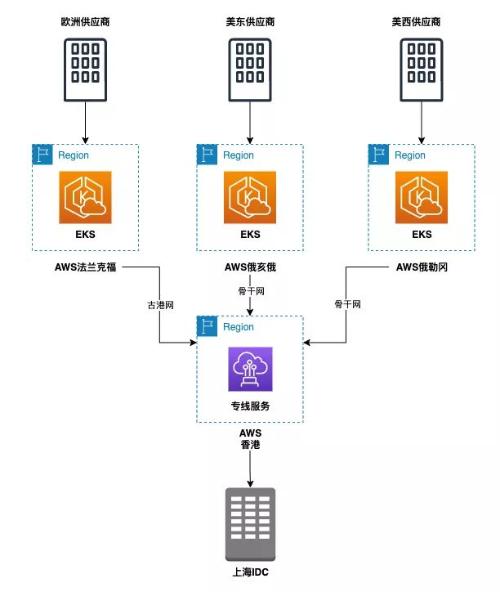
2. Reduce network latency
Use AWS Global Data Center to access your nearest vendors
Many abroad
The provider's services are deployed around world
And all our foreign visits
Everyone exits agent
Some server deployments like this
Suppliers take longer due to physical distance
The reason is that network latency is high
Via AWS data centers around world
We can deploy service next to provider
Near computer room
Concurrent use of the AWS backbone
Reduce each datacenter to a proxy
Latency of AWS data centers near this location
Last
Along selection
Connect AWS Data Center and Ctrip IDC
See rice. 5
Whole process
For those who are at a distance
Has a bigger impact on network latency
Supplier performance has improved significantly
Up to 50% reduction in response time
Picture 5
4.2 Continuous architecture transformation, performance and cost optimization
In current plan
We are for cloud
Independently developed a new set of applications
Problem with this
When business changes happen
We also need to customize
Two applications deployed on Ctrip IDC and AWS
Increased system maintenance costs
Main reason
This is a base component that heavily depends on Ctrip in source application
This time in cloud
Attempt to use
Fully independent VPC account and network
Deploying a set in cloud is unrealistic
First, price is too high
Second
Some sensitive data cannot be stored in cloud
We will follow
Optimize adapter architecture
No dependencies
In case of Ctrip main components
Reuse a set of applications to adapt to different cloud environments
After starting a business
To test more load in future
The ability to move to cloud
We are also working on performance
Continuous cost optimization and high availability
4.2.1 Using Cloud Elastic Scalability
Let's take cost of computing resources as an example
Instance cost calculation = instance running time
Instance price
If everything was simple
Roughly change mode of operation of local computer room
Apply to cloud computing
Cloud Computing
The cost of resources is higher than local computer room
So here we are
Make full use of cloud-on-demand charging
Reduce cost of idle resources
Instance started
Duration and number of services in a Kubernetes cluster
and assigned
The computing resources of these services are proportional
The number of simultaneous services is proportional to traffic
Hotel Direct Connection Business Scenario
There is unpredictable business traffic
For example, tourism policy released before holidays
Or live marketing events
Elasticity in Cloud
Well-used features
Smart resources to deal with sudden traffic
Kubernetes HPA Elasticity
The structure will be assembled in real time
Overall cluster load index
Elasticity conformity assessment
Scaling conditions and module scaling
It's not enough to simply scale a module
We should also be aware
Use cluster autoscaling feature in cluster
Monitoring cluster
Due to insufficient resource allocation
Pods that cannot be scheduled normally
Automatically fromcloud platform instance
Application for adding nodes to pool
Same time in traffic
When falling
Cluster autoscaling component
It will also detect in cluster
Nodes with low resource usage
Package
Scheduled for other available nodes
Dispose of this portion of idle nodes
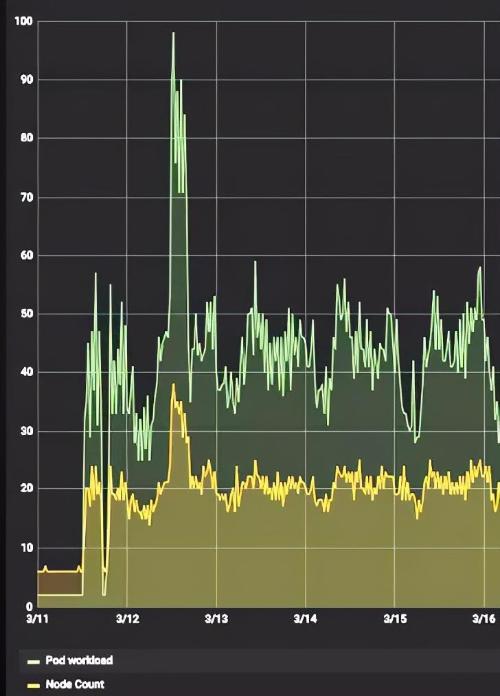
Elastic scaling
Elasticity in Cloud
Functions don't just help reduce resource usage costs
Also improve service
Fault tolerance to infrastructure failures
In infrastructure section
Availability Zone Break Period
Other regions available
An appropriate number of nodes will be added
Continue so that entire cluster is available
Kubernetes supports pods
Required CPU and memory settings
Find a reasonable quote at a reasonable price
Achieve maximum performance
So here we are
Before service moves to cloud
Perform real world load testing
See changes in business traffic
Impact on cluster performance
Business Frequency
Peak and low peak loads
Service bottleneck in resources
Adequate Margin
The resource buffer needs to handle peak traffic, etc.
Not because
Actual usage is too high to cause stability issues
For example, OOM
Or frequent CPU throttling
It won't waste resources because it's too small
In end
Even if your app only uses 1% of instance
Also pay 100% of copy price
4.2.2 Using staking instances in public cloud
Some cloud platforms
Some idle compute resources will be used as spot instances
Lower than On-Demand instances
Stakes, as name suggests
Final copy price
Based on market supply and demand
According to our real experience
If not
Prices for particularly popular models are generally set on request
About 10-30% of cost of a copy
Inexpensive Spot Instances naturally have their limitations
Cloud platform
The rate is subject to adjustment
Instance pool resource ratio restarts some instances
The chance of overall recovery is usually <3% statistically,
Simultaneously
These instances will be notified 2 minutes before reuse
Usually we
Terminal handler component provided by AWS
After revocation notice
Schedule container for other available instances in advance
Resources reduced
Impact of review on service
The figure below shows division of cloud resource pool to host instances
We see
Even same instance resources
This is also an independent pool of resources in different Availability Zones

Picture 6
To be
Minimize Impact of Spot Instances on Outages
Include examples
Impact of rebalancing across multiple availability zones
We are passing
ASG (AWS Autoscaling Group
Elastic expansion group
When choosing different types of instances
Add different instance resource pools
Independently use ASG for control
This ensures maximum resource efficiency
Picture 7
Ctrip Hotel
Direct use of on-demand instances and spot rates
Mixed instance deployment
Guaranteed low cost and high availability
Some Key System Components
For example, cluster autoscaler
Stateful service that loses data when interrupted
For example, Prometheus
Launch instances on demand
And high error tolerance
Flexible use
Stateless business applications run on point instances
Nodes via kubernetes
Affinity manages different types of services
Scheduled for an instance of corresponding type tag
See rice. 8
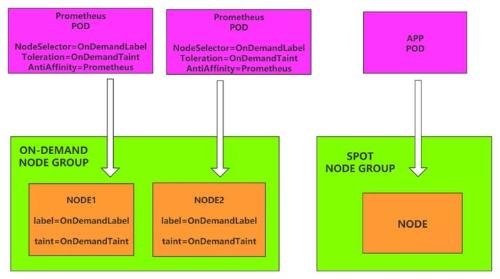
Picture 8
Skip
kubernates
Native HPA components and ClusterAutoscaler
Combination
Full use of AWS ASG and staking resources
Can save 50-80% on costs
4.2.3 Optimizing DNS resolution performance
When serving
When zooming in gradually
We found
Call latency between services has increased significantly
On average it reaches 1.5 s
Peak reaches 2.5 seconds
After analysis, it was discovered
Mostly
Because DNS resolution load is too high
Bottleneck in performance analysis caused by
Finally, we are accepting a larger community
local method
Run local cache for domain names with hotspot resolution
To shrink core
Frequent DNS resolution requests to improve performance
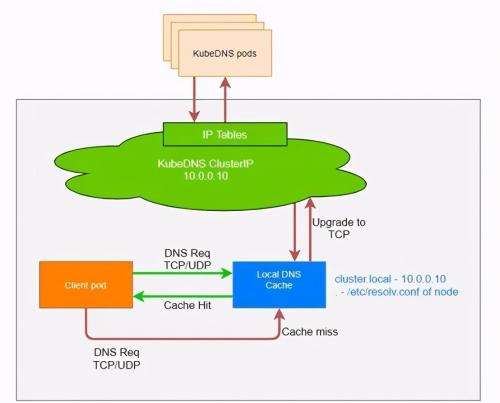
Picture 9
As shown in fig. 9
At each node
DaemonSet based deployment
NodeLocal DNSCache
Skip
LocalDNS host
CoreDNS Mitigation
Service DNS query load
LocalDNS cache will listen
On node
Query DNS resolution for each client module
Tuning with local analysis
Local DNS cache
will first try to resolve request via cache
Go to CoreDNS if you missed it
Query analysis results
and cache it for next local parsing request
As shown below
Using LocalDNS scheme
We will have peak latency
Decreased from 2.5s to 300ms
An 80% reduction in response time:
Before using LocalDNS, average response is 1.5-2.5 seconds
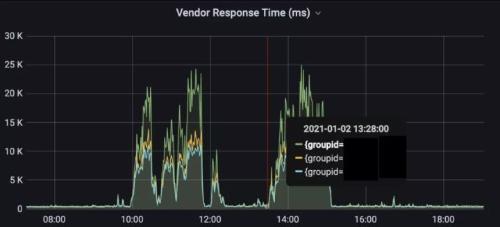
Before optimization
After using LocalDNS solution
Reducing number of requests per response
Up to 300-400ms latency is optimized by 80%
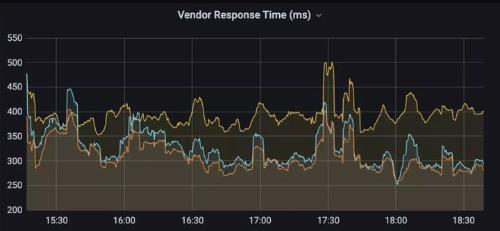
After optimization
4.2.4. Optimize Public Cloud Traffic Across Availability Zones
used
After bidding instance has greatly optimized resources
We noticed
Cross-Area Traffic Increases Significantly After Maintenance
Very high share (60%)
This is because when called between services
We have service centers
Deploy across Availability Zones
Maximum service availability
At same time, problem is that
A large number of traffic interactions between services
Inter-availability zone traffic charges
See rice. 10
Picture 10
However
For high availability of entire system
We don't want to deploy service in a single Availability Zone
Shorten service SLA
We need
Reducing traffic between Availability Zones
Guaranteed high service availability
Finally, after various studies of program
We use AWS NLB to provide services
Disable cross-az via NLB
For upstream and downstream of same Availability Zone
The service controls traffic availability zone
Simultaneously
Use previously mentioned local DNS component
Access upstream service for NLB
Improved domain name resolution for different availability zones
Guaranteed outgoing and outgoing service traffic
Only relationship within availability zone
As shown below after conversion:
Picture 11
Previous paragraph
The service will go through the K8s Kube proxy
Create cross-availability zones and cross-sites
We choose
Using externalTrafficPolicy
Local Policies
Transfer traffic
Fixed on localhost service
But also local
The strategy also brings some problems
See rice. 12
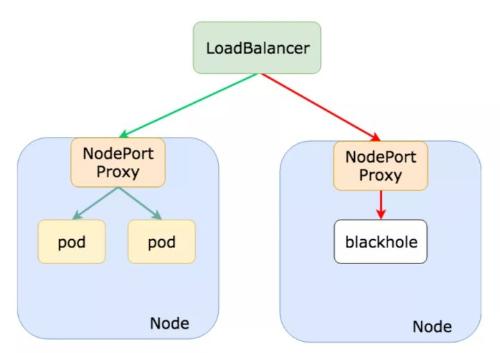
Picture 12
As shown above
Local Policies
This may be due to distribution of server services
Imbalance leads to black holes in traffic and services
Unbalanced load
So, based on this
We use EKS to scale group policies flexibly
Balanced resource allocation of base nodes
Different accessibility zones
Simultaneous use of K8 anti-close strategy
Distribute service as widely as possible
Navigate to nodes in different availability zones
Maximum traffic balance guarantee
Although guaranteed
High availability deployment of services in cross-availability zones
Optimized Range
Availability Zone traffic decreased by 95.4%
See rice. 13
Picture 13
5. Further directions for optimization and improvement
Current structure
Although some issues in our business have been resolved
But still
There are some flaws that can be fixed
To visit nearest supplier
We use an independent VPC network
To deploy and test our cluster
So you need to be alone
Deploy related storage dependencies to cloud
And log monitoring components
This will surely increase
Difficulty in operation and maintenance
And difficulty of transferring services to other clouds
Recent
The solution to this problem in architectural design
We plan to make following changes
First
Need to compute in cloud and
Use persistent data storage
Move back to Ctrip IDC
Thus, this part of data does not need to be transferred to cloud
Secondly, thanks to company
Other Data Centers in AWS
There is already a mature environment
So here we are
To pass, you only need to cooperate with OPS
Two
VPC network between AWS data centers
You can use company registration and monitoring system
Reducing operating and maintenance costs
6.
Ctrip Hotel directly connected
What I said
The practice of using cloud technologies
How to quickly create a set in cloud
Stable and efficient production environment for fast delivery
Smart sustainability
And some in cloud
Cost optimization
With help of cloud system
Infrastructure automation
Release of part of operation and maintenance work
You can invest more in business development
Respond more flexibly to recurring business requirements
With monitoring and logging
Rapid trial and error and feedback
I warn you
More teams looking to move to cloud
Less detours, take advantage of cloud



Related
How does Ctrip system work? I am a technical data operator of Ctrip. Let me talk about this with AWS.
I am a Ctrip system technician. I am also the owner of several hotels, hotels, people and markets. I summarize 100 points
Our Ctrip AI: from recommendation to system cloudiness, from algorithm to formula, how does it work?
Hotel How does Ctrip OTA work? How it works? How do OTAs work, what are rules?
What does a hotel do. There is a market with a price of 10,000 yuan. I am using AP base point to decompose it. let me tell you
What does a hotel do. There is a market with a price of 10,000 yuan. I am using AP base point to decompose it. let me tell you
How does Xiaohongshu marketing work? What system model? What is the marketing strategy? let me tell you
How does Meituan.Hotel OTA work? let me tell you
Three Enlightenments in Hotel Management. I am using this. Broken window effect. Tell me about it.
Ctrip. How to use pyramid reward method in hotel system. Do it well. What kind of activities would you like?